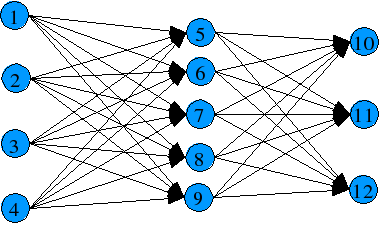
This neural network has 4 inputs, 3 outputs and 5 hidden-layer neurons.
GA-NN-AG
Well, obviously is an acronym. Actually it means Genetic Algorithm - Neural Network - AGgregative. This is the original branch of the project.
The concept behind isn't new (using a genetic algorithm over a bunch of neural networks to optimize them), so if there is something new, is in the implementation. This text is just an introduction of the ideas behind the code.
At startup (I mean generation 0), a group of classical feedforward backpropagation networks (a network constructed by layers of neurons) are used as individuals of the genetic algorithm. For example, these 2 neural networks
Individual 1:
This neural network has 4 inputs, 3 outputs and 5 hidden-layer neurons.
Individual 2:
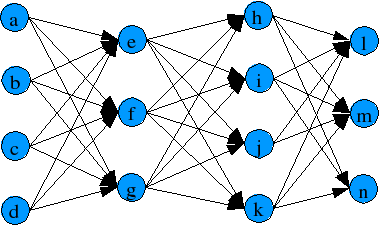
This one has also 4 inpust and 3 outputs, but has 2 hidden layers with 3 neurons in the
first hidden layer and 4 in the second.
There's nothing new, up to this point, just two feedforward neural network.
Now let's talk some particularities of the implementation of these networks.
Instead of the standard array of neurons, the network are defined in a spatial
cartesian coordinate system (normalized), so every neuron got a plane coordinate:
"(x_c , y_c)". Coordinates are set increasing from
left to right, and up to down (image-processing style).
Connections between neurons are defined as a vector formed by two
pairs of coordinates, the destiny pair and the origin pair.
The strong point of this implementation is that adding or deleting components
could be done without affecting too much the other components.
There aren't global parameters for the whole network, almost every single parameter is defined in a per neuron basis (These includes learning-rate, bias-correction, bias-value, momentum-learning, threshold-function, etc ...). This require a lot more memory than a more orthodox implemetation.
You may thinking "what a clumsy / inefficient way to implement a neural network". Well that's true, it's a lot less efficient than the traditional array. Then why bother using a less optimum implementation?
The answer is a bit long and indirect. A neural network isn't a universal problem solver, nor unique system. For every problem (suitable problem) lots of networks that solve it could exist (and lots more that couldn't). The problem, is that all these "candidates" could have different number of layers, different number of neurons, different learning rates, and so on. Finding a fixed set of parameters to describe the topology of all these networks is a difficult task, unless we use an incredible big set of parameters (big enough to contain every posible case). So, instead, we accept the unavoidable fact, and use a variable size set of parameters. This set is the gene (or blueprint) of the network.
With a variable length gene, it's a bit difficult to cross between adequate networks (at least in the traditional way, say putting a cut point, and then use from this point forward, the blueprint of the other). Here the spatial representation of the network becames handy. Instead of using a cut point, a cut region is used, as showed:
Cut region for both neural networks (red region):
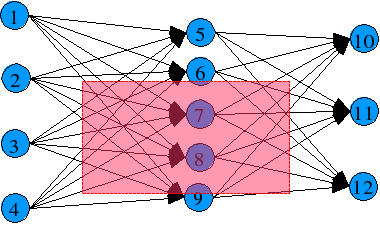
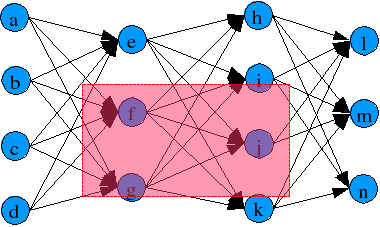
Let's say that the neural network 1 is the parent1 (the receptor) and network 2
is parent2 (the donor or whatever you wanna call).
For the receptor, the neurons inside this area are wiped
out, and got replaced by neurons of the donor inside the cut area.
Connections in the receptor coming and going
to the deleted neurons are severed, and new connections to the newly
implanted neurons are made. Connections inside the implanted area
aren't touched. This also applies to connections outside the
cut area. Because the only connections that are affected
are in the border zone of the cut region, most of the already trained weights
within or outside de zone are preserved. The resulting network would look like
this:
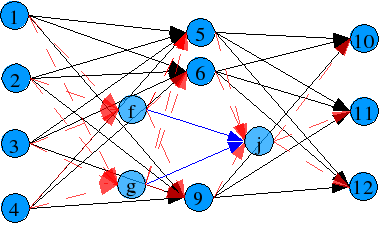
Black arrows are non touched connections from parent1 (receptor), blue arrows are non touched connections from parent2 (donor) and red arrows are new connections.
Surely you have realized that a lot of possible scenarios could appear: no neurons got replaced (cut region too small), no neurons got wiped out (cut region contains neurons just in the donor), single neurons got replaced by multiple (the case showed), etc ... all this scenarios (and every other you can imagine) are accepted since it represents some useful events. For example: if nothing got deleted nor added, then a cloning event happened (like amoebas), so a parent could breed with element of another generation. Or if some got deleted, but nothing is added, then it got crippled (well it's quite possible that isn't crippled, instead it become more efficient), and so on.
Because of this "refining" method, the resulting networks after some generations could not have which in a standard network is known as layer, and that's the reason for using neurons as individual entities, and not part of a layer. As more and more generations pass, the resulting topology could be very different to the starting ones, up to the point that something like a layers couldn't be recognized.
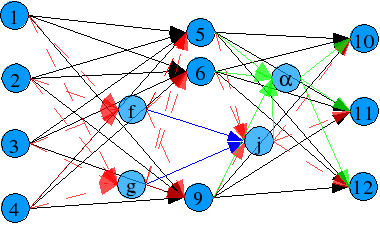
And there's even more chaos. We still haven't talk about the mutation. Mutation is done in two level: neuron (modification of one parameter in the neuron, such a learning-rate, bias, connections, weights, etc...), and network (adding some random parameter neurons to the network in random position).
An example of network mutation, with one neuron add:
Now an explanation of the "AGgregative." part. Aggregation as used here is just the increase of the capacity of a network in steps and not as whole from start. Got it clear? maybe not, so lets use an example to get the picture.
Suppose that you got a solution for certain problem, let's say pattern matching over 20 patterns. But now, you realize that you need more than 20 patterns to recognize, let's say 22 patterns. Normally you will remade all the work for all the 22 patterns, and throw away all the 20 patterns solution. Here is where the aggregative concept becomes helpful.
In this case, you have a 20 patterns solution, so what you have to do is to add the 2 extra patterns in the output. The system has the ability to add these outputs neurons plus the connections, and also adds some hidden layer neurons. The result could look like this:
An example of aggregation. Pretty messy:
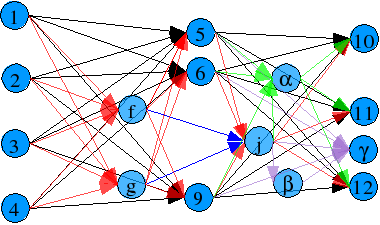
Now you need to retrain. But this doesn't seem better than just redoing everything with 22 patterns. After all, you have to retrain everything. Well that's true up to a certain level. The reason to use aggregation is to preserve the old system, and add new capacities to it. This is controled by one parameter, defined for every connection, the age. A new connections have an age of 0. Each time a connection is released (the neuron owner of the connection is part of an already trained network), it's age is increased by one. The age of the connection affect it's learning capacity in a inverse exponential form, so only relative new connections are easily trained. That makes our hard learned connections not to be trashed so easily. But that also makes our old dog not able to learn new tricks. It's up to the user to decide to use or not this capacity.
Well, some footnotes about the system. It works in a client-server fashion, since every neural network is an independant process, which is controled by a client of a server, that runs the genetic algorithm. So, the system could run the clients in different machines at the same time. It's not a marvelous cluster system, it has no load balance at all, but it works. Maybe a little more work is needed here. It could run also in a cooperative way, with multiple servers running in multiple machines, interchanging breeds between them (a multi niche environment).
An end note about an interesting finding: the existence of "genius" networks, I mean networks with high learning rates. This networks appeared randomly, and the parameters conforming it are random. Threshold function, momentum and other parameters aren't unique for the whole network, eventhought they could share the same topology with other less "adequate" networks.
Nothing left to said, except that this branch will not include more capabilities in the near future (just bug correction, please feedback), all new ideas are added in the new branch (which needs a lot of work).
Copyright 2004-2005 Oswaldo Morizaki Hirakata